K平均法(k-means clustering)とは Scalaでサンプルを実装する
今回は機械学習ネタです。
教師なし学習というものにk平均法(k-means clustering)というアルゴリズムがあります。
普通ならpythonで実装しmatplotlibとやらで結果を視覚化すると思いますが、
matplotlibの使い方がわかりません。
ですのでScalaで実装してjavafxで視覚化したいと思います。
k平均法のアルゴリズム
k平均法を構成するもの
- クラスタ… ニュアンスが正しいかわかりませんが、グループだと捉えればいいのかなと思います。
- 入力データ… クラスタに所属させる
学習の流れ
だいたいこんな流れになるかと思います。
- クラスタを初期化する… 好きな値で大丈夫だそうです。
- データをクラスタに所属させる… クラスタとデータの距離を計算してその値が最小になるクラスタに所属させる
- クラスタを更新する… クラスタに属しているデータの平均をクラスタの値とする
- クラスタの値が変化しなくなるまで2,3と繰り返す
2でクラスタとデータの距離を計算するのですが、ユークリッド距離というのを使うらしいです。
以下のように計算します。
√(データx – クラスタx)² + (データy – クラスタy)²
以下のようにクラスタとデータが定義されているとします。
クラスタ A(2, 7), B(5, 2), C(6, 1)
データ (4, 3)
すべてのクラスタに対してデータとのユークリッド距離を求めます。
クラスタが3つあるため3回計算してその中から答えが最小になるクラスタにデータを割り振るということですね。
それぞれのクラスタとの距離はこうなりました。
A… 4.4
B… 1.4
C… 2.8
ということなのでデータ(4, 3)はBに属するということです。
今回はデータが一つだけですが、データが複数個あればそれぞれのデータに対するクラスタとの距離を計算してクラスタに割り振ります。
3の処理でクラスタを更新します。
たとえばクラスタAに以下のような四つのデータが属しているとします。
(6, 2) (3, 5) (7,5) (6, 4)
これらのデータの同じ要素の平均をもとめると以下のようになりました
(6 + 3 + 7 + 6) / 4 = 5.5
(2 + 5 + 5 + 4) / 4 = 4
ですのでクラスタAの新しい値は(5,5, 4)になりますね。
4は上で示した2,3の処理を繰り返すだけです。
クラスタの値が変わっているので、それに割り振られるデータも変化します。
実装しよう
K平均法をプログラムしてみたいと思います。
import javafx.application._
import javafx.stage._
import javafx.animation._
import javafx.scene.shape._
import javafx.scene.Scene
import javafx.scene.layout._
import javafx.scene.paint.Color
import java.math
import scala.util.Random
// エントリーポイント
object KMeansMain
{
def main(args: Array[String])
{
Application.launch(classOf[KMeansVisual], args:_*)
}
}
// 割り振りと更新を行うクラス
class KMeans
{
// データの数
val dataNum = 1600
// クラスタの数
val cNum = 4
// ここから
var r = new Random()
// 学習の流れの1
var cluster = Array.fill(cNum)(Array.fill(2)((r.nextInt(500)).asInstanceOf[Float]))
val data = Array.fill(dataNum)(Array.fill(2)(0.0f))
val gr = data.size/cNum
for (i <- 0 to data.size-1) {
data(i)(0) = r.nextInt(250) + r.nextInt(250) * (i / gr)
data(i)(1) = r.nextInt(250) + r.nextInt(250) * (i / gr)
}
// ここまではいろいろしてデータを作ってる
// どのデータがどのクラスタに属しているかを格納する配列
var indexOfAssign = Array.fill(dataNum)(0)
// データをクラスタに割り当てる
// 学習の流れの2
def assign() {
for (d <- 0 to data.size-1) {
var distArr = Array.fill(cluster.size)(0.0)
for (c <- 0 to cluster.size-1) {
val x = data(d)(0) - cluster(c)(0)
val y = data(d)(1) - cluster(c)(1)
distArr(c) = Math.sqrt( Math.pow(x,2) + Math.pow(y,2) )
}
indexOfAssign(d) = distArr.indexOf(distArr.min)
}
}
// クラスタを更新する クラスタごとのデータの平均を求める
// 学習の流れの3
def update() {
for (c <- 0 to cluster.size-1) {
var xSum = 0.0f
var ySum = 0.0f
for (i <- 0 to indexOfAssign.size-1) {
if (indexOfAssign(i) == c) {
xSum += data(i)(0)
ySum += data(i)(1)
}
}
val num: Float = indexOfAssign.count(cInd => cInd == c)
cluster(c)(0) = xSum / num
cluster(c)(1) = ySum / num
}
}
}
// 描画をしてくれるクラス
// 今回の議題ではないのでそこまで重要ではない
class KMeansVisual extends Application
{
// 図形を描画するために使う
val pane = new Pane
val shapes = pane.getChildren
// KMeansクラスをメンバにもつ
val km = new KMeans
// ウインドウの大きさ
val w = 900
val h = 900
// 矩形の配列 クラスタとデータ
var cRects: Array[Rectangle] = null
var dRects: Array[Rectangle] = null
// クラスタごとの色
var colors = Array(
Color.web("0x000000"),
Color.web("0xff0000"),
Color.web("0x00ff00"),
Color.web("0x0000ff")
)
// 矩形をペーンに加える
override def init() {
cRects = Array.fill(km.cluster.size)(new Rectangle(20,20))
for (rect <- cRects) {
shapes.add(rect)
}
dRects = Array.fill(km.data.size)(new Rectangle(5,5))
for (rect <- dRects) {
shapes.add(rect)
}
}
// 割り振りと更新を別スレッドで行う
// 学習の流れの4
// ※クラスタの値が変化しなくなったかを判断する処理は実装してません。
override def start(stage: Stage) {
stage.setScene(new Scene(pane, w, h))
stage.show
new Thread()
{
override def run() {
while(true) {
km.assign()
km.update()
Thread.sleep(80)
}
}
}.start
new AnimationTimer()
{
override def handle(now: Long) {
draw()
}
}.start
}
def draw() {
for (i <- 0 to km.cluster.size-1) {
cRects(i).setFill(Color.web("0xaabbcc"))
cRects(i).setX(km.cluster(i)(0))
cRects(i).setY(km.cluster(i)(1))
}
for (i <- 0 to km.data.size-1) {
dRects(i).setFill(colors(km.indexOfAssign(i)))
dRects(i).setX(km.data(i)(0))
dRects(i).setY(km.data(i)(1))
}
}
}
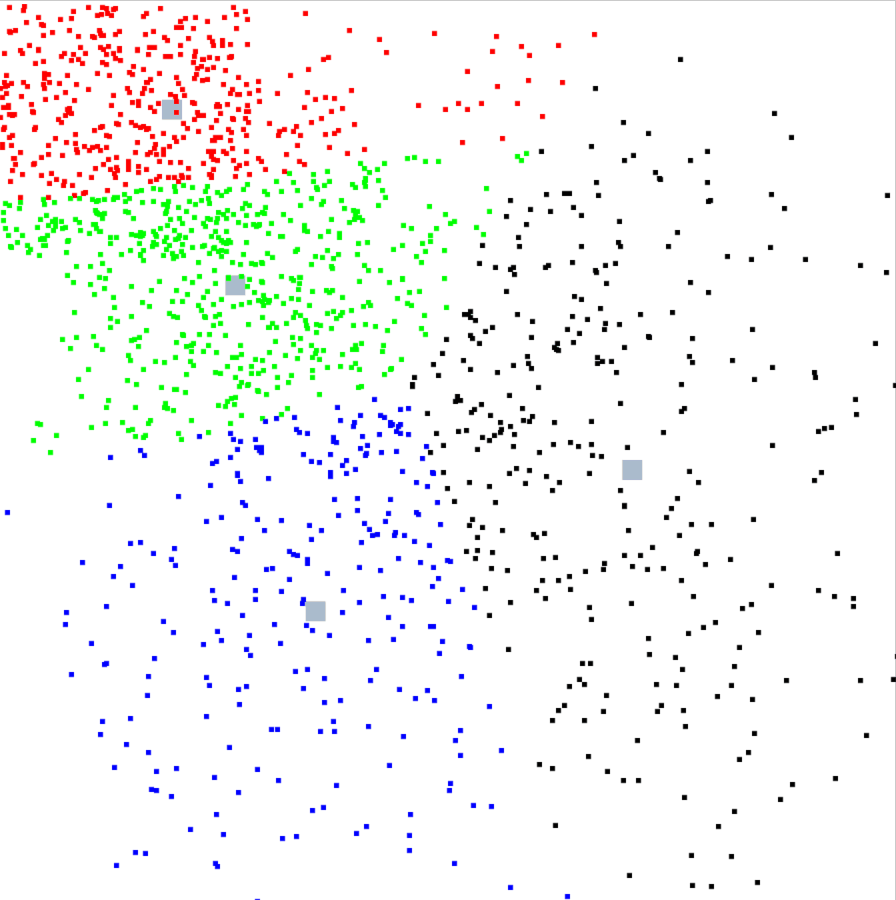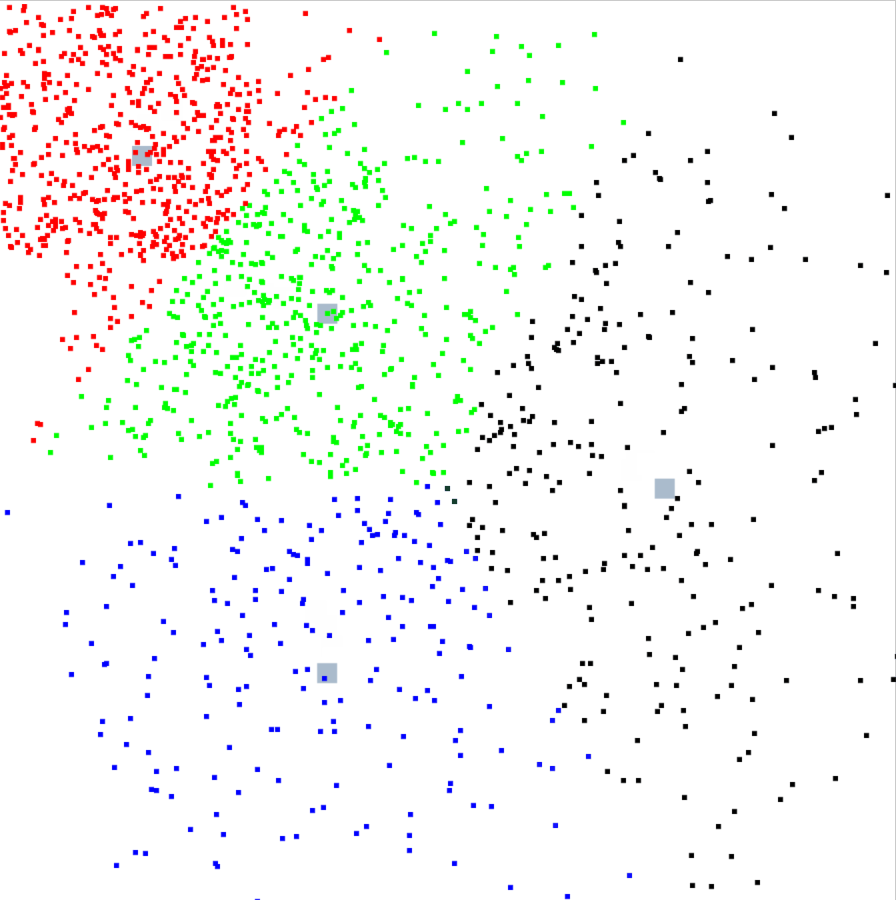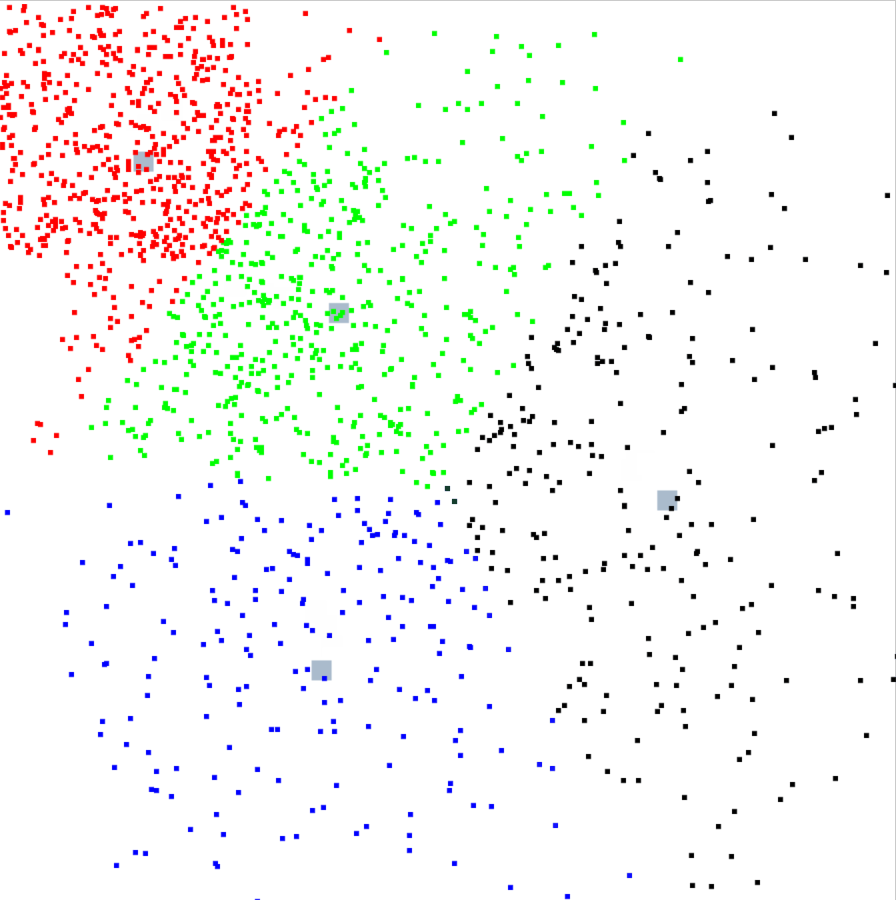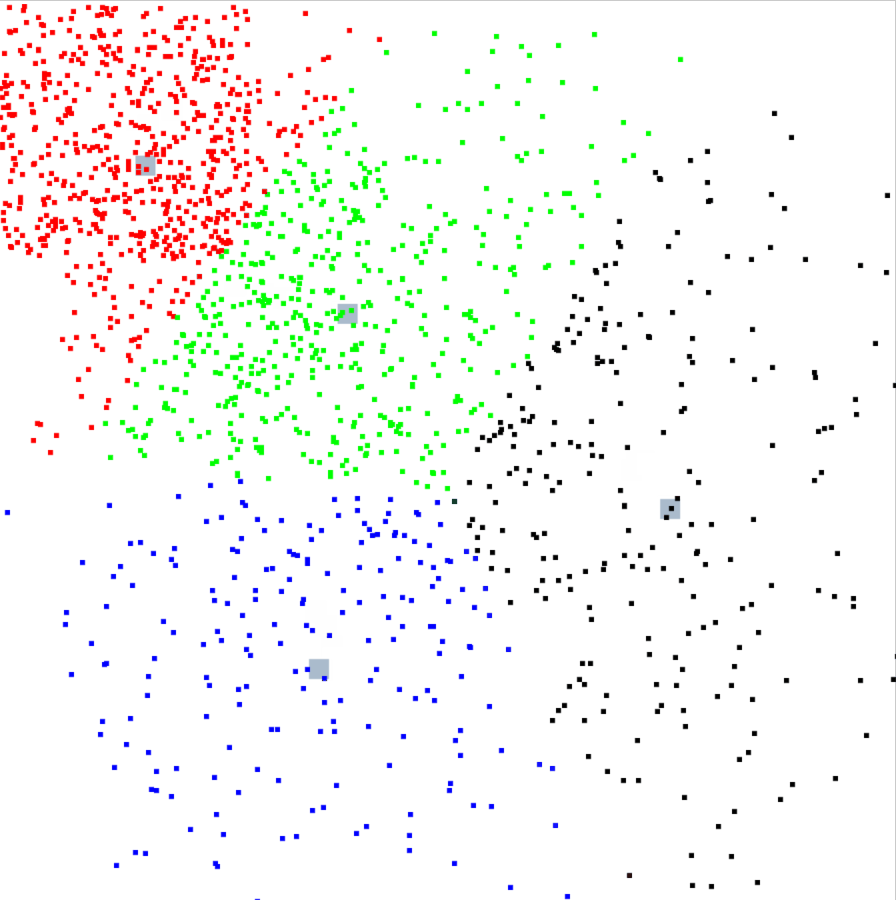
クラスタの動き
クラスタとデータの値はランダムなので実行するたびに結果はかわりますが、今回はこんな動きをしました。
クラスタごとに色をつけたのですが、見てるだけでも面白いですね。
僕は機械学習のプロではないので知識が乏しく、間違っている部分があるかもしれません。
その際はご指摘いただければと思います。
k平均法は書籍はネットに情報が結構あると思います。
僕は以下の書籍でk平均法をすこしだけ勉強しました。
Pythonで動かして学ぶ!あたらしい機械学習の教科書 第2版